
I am trying to archive lefty reddit in the likely off chance that these subs get nuked. Any more subs to add to the list? Any advice on going about archiving it? What should I do with in bedded links?
Perfect timing, I was just talking about that. What format do you have? If its json, we could import it to Lemmy through the api.
Grabbing posts and comments from the Reddit API would be easy. Would the markdown need the be transformed?
I think its exactly the same, just user/subreddit links wouldnt work.
How do you deal with the name of the poster, since they don’t exist in the Lemmy DB?
Either create an account with that name (only really possible if its a separate instance imo), or you post it all from a user like
communism_backup.The
communism_backupoption seems more reasonable to me. Every post could have the original username from Reddit written at the end of its body and the same logic applies to the comments.It also considers people who may want to join Lemmy with their original account usernames.
Hahaha
-7deadlyfetishes
-7deadlyfetishes
deleted by creator
Yea it is in json, I will send you the files through whatever means you would like. Have only got Communism so far
I guess we could put them into something like !communism_archive@lemmygrad.ml or similar.
Isn’t there !reddit_post_archive@lemmygrad.ml exactly for that purpose?
I’d suggest not having the _archive so the sub can have continuity
That would just cause problems, because you would have posts from Reddit and from Lemmy right next to each other. It wouldnt be clear which users you can actually talk with. Might be better to make a completely separate instance for that. Maybe reddit.lemmy.ml?
Hrm… It’d probably be fine as an import directly into the community, as long as the published_dates for all the posts and comments also used the correct times. You’d see very obviously that the creator is
data_hoarderor whoever, and all the comments are in there.Obvi we’d want to test locally before actually doing the import.
If the user names all had _archived appended then that would be clear. Can one also lock participation on a thread?
yep you can lock threads.
So I’d advocate for keeping unique names for Reddit users but probably obfuscating them to be polite and locking the archived threads
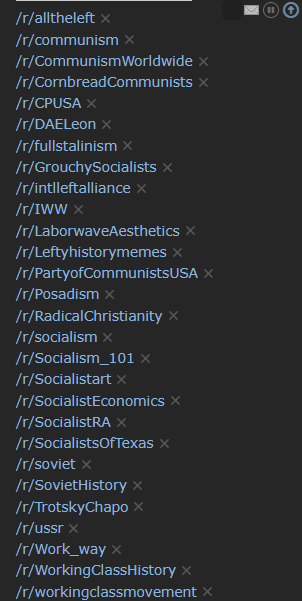
This is my left wing multireddit. Hope this helps.
evvvv CPUSA. But 4 real thanks for this I will have to hit some of those up
I know, I’m just a former member of the party and I have a sentimental heart.
Another possibility would just be using a tool like scrapy, creating a list of subreddits to scrape. I could test this out on a smaller subreddit sometime today. It wouldn’t be nice json, but it’d at least be a comprehensive and simple way to back it up.
I’m looking into scraping the json. Scrapy would be awful
Ya I’m trying it out, and its not going well @Closesniper@lemmygrad.ml . Reddit blocks all of these scrapers, esp on comments. They want you to use their json API, which is understandable.
yea same here i am getting a headache trying to get this to work, if we would want comments it would have to be manual. I am trying something so will update soon if I can get this program to work.
I’m able to get the banned subreddit data through the pushshift API in Python! I think we can recreate the banned subs
Nice!
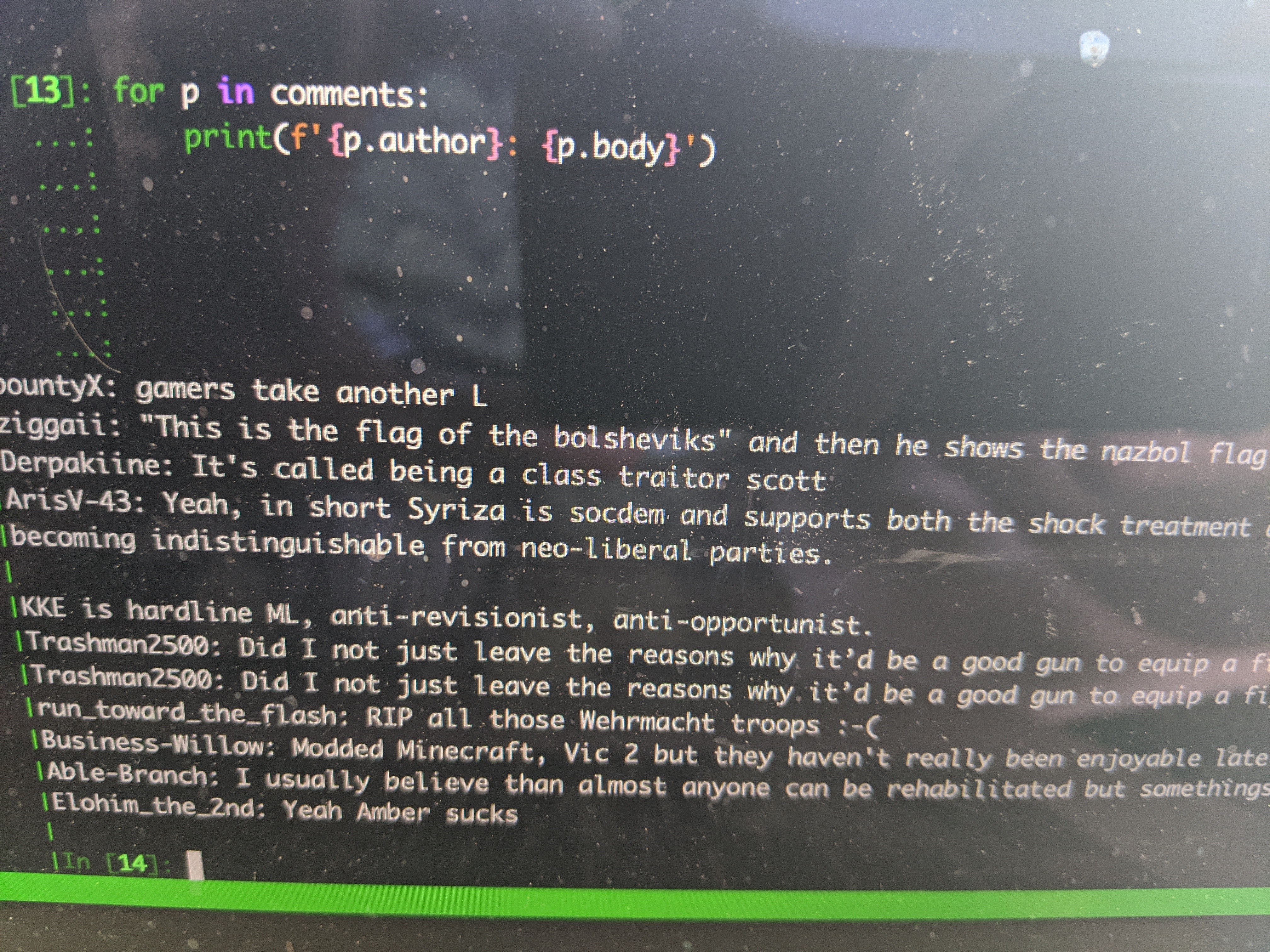
Sweet!
I will look into that option, and yes if you could test it out on some smaller subs that would be helpful
The main important thing to me is to have comments. Does this store those too?
Also what tool are you using, just a crawler? I could only find bulk-downloader-for-reddit, yet it doesn’t store comments, just links.
Also you got the main ones for me. I really only care about the educational subs, /r/communism101, /r/communism, /r/socialism_101.
Yea that is the exact program I will be using. I think it will be a pain in the ass but I think I will manually do comments, maybe try and get people together and crowd source them
Dang, ya it looks like that tool at least doesn’t support comment downloading. It’d probably be a good idea to try to work that functionality in there somehow.
You could use the Reddit API for that. There should also be an endpoint for the post itself, or maybe thats included if you fetch the subreddit post listing.
@Closesniper@lemmygrad.ml I’m sure that bulk-downloader-for-reddit is using PRAW, the python reddit API, so it does already a good API access there, it’d just be adding that functionality to it.
I can use the reddit API however I gotta do it post by post which will be a drag, will look into seeing if I could simplify it in some way
you could loop throw the backed up posts and requests comments for those. that way you can script it at least.
This would be trivial in Python.
Do you know if anyone archived MTC or MMTC?
Yes
where can we find it?
It’s a ton of json and image files with random base 64 names. Not human navigable. I’m thinking the admins here can load it into Lemmy and I’m working with them on that.
Okay so I tried and I can get data from MTC. Some of the images hosted by Reddit are taken down but not all.
I’d propose injecting all this data into existing subs using a user called archive_bot or data_horder or something. The original author’s name or a unique obfuscation of it could be put at the top of each comment so threads could be readable
Reddit probably wouldn’t like this and I dunno if they’d take legal action. Their TOS says data can be displayed by third parties but you’re supposed to abide take down requests, though the original author and not Reddit is the “owner” of the data. Maybe those posts should require a log in to view to prevent search engines from finding it.
Edit: one can’t simply upload all this to Lemmy because all the posts and comments will need to link to each other through foreign keys in the database, and those won’t be the same keys Reddit was using
I will look into making some sort of system or website like you suggested, but I will probably need some help doing this cause when I said I was gonna archive everything I didn’t expect it to be this difficult. I am gonna reach out to some people for help, maybe make a forum or something IDK.
I will make a new post with updates very soon.
I have have MTC archived and a script to do it for any sub
damn dude, comments and everything? I already have the subs listed archived, so just in case u get swatted by the feds or some shit we have a backup at least lol.
Yeah comments and 2.5 gigs of images Reddit was hosting just for MTC. That’s a lot of memes haha
Jesus dude, ill let you do the backup cause I cant even get comments and can only get 1k-2k posts off of each sub
Once you get some sample
.jsonwe could use, we could write and test a pretty simple importer.I got a sample, it is what I could gather from r/alltheleft, here is the dropbox link if ya want it
https://www.dropbox.com/sh/nqtotouc3i1yg9l/AAA1VP7RTLplywBr7cO1GPyPa?dl=0
What’s the best way to do this? Are you on GitHub? I could make a private repo (with the code for archiving and a sample of the json) and share it with you.
Ya I’m on github, that’d be a pretty easy way to do it. Also make sure some comments come with it too, that’d probably be the most difficult part to script.
deleted by creator






{kind=link}