- cross-posted to:
- privacy@lemmy.ml

- cross-posted to:
- privacy@lemmy.ml
Not sure how that will affect libreddit or teddit. That’d would prevent me to get some news on specific channels, which when interesting enough, I brought to lemmy, :)
Reddit Wants to Get Paid for Helping to Teach Big A.I. Systems
You must log in or register to comment.
This news is what brought me back to check out Lemmy. I‘m just not gonna pay just to be able to use an alternative app to browse Reddit, no way, I‘d rather dump Reddit entirely.
The only social media I’m willing to pay for is community developed social media. I’ll gladly donate to support Mastodon and if Lemmy gains enough popularity I regularly visit I’d donate to support it too, but screw paying for “premium” “features” on corporate social media that is actively taking away from users to make the paid option more attractive.
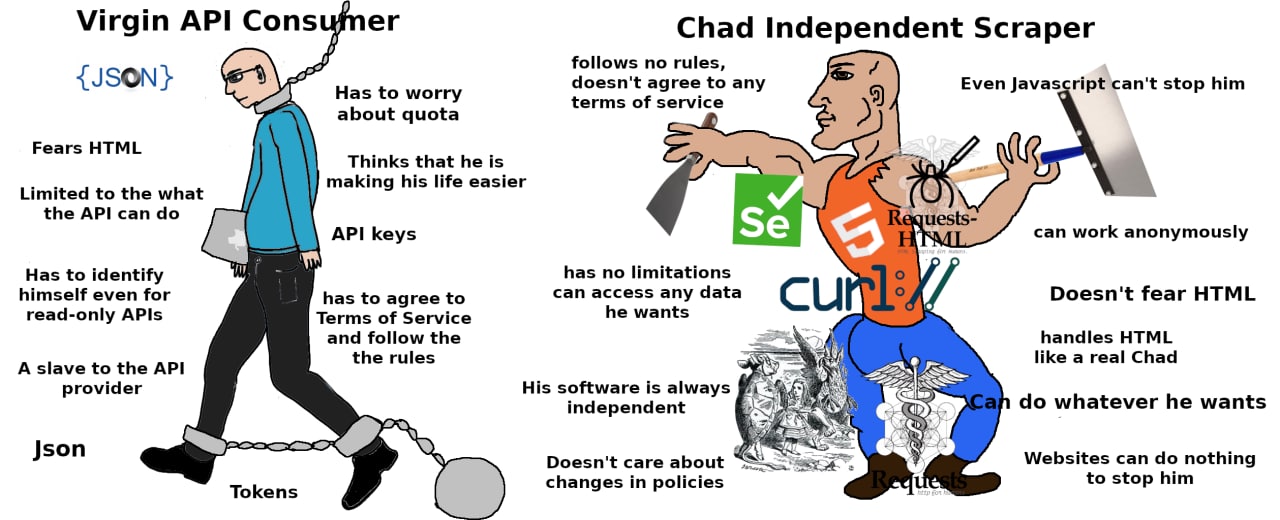
Edit: alt text below. The OCRbot would (understandably) have trouble with this one. @CannotSleep420@lemmygrad.ml
Virgin vs Chad meme.
On the left, virgin, captioned “Virgin API consumer,” wearing a blue long sleeve shirt and black pants and shoes, and holding a mac book. There is a collar and chain around his neck, and a ball and chains attached to his feet. Numerous text bubbles and logos surround him: “JSON”, “Fears HTML,” “Limited to what the API can do,” “Has to identify himself even for read-only APIs,” “A slave to the API provider,” “Json,” “Tokens,” “has to agree to Terms of Service and follow the the rules,” “API keys,” “Thinks that he is making his life easier,” “Has to worry about quota.”
On the right, chad, captioned “Chad Independent Scraper,” wearing an orange tank-top (with the HTML 5 logo on it), blue pants, and brown shoes, and holding two different types of paint scrapers, one in each (outstretched) hand. Numerous text bubbles and logos surround him: “follows no rules, doesn’t agree to any terms of service,” Selenium logo, “has no limitations can access any data he wants,” cURL logo, “His software is always independent,” “Doesn’t care about changes in policies,” unknown logo, Python Requests library logo, “Websites can do nothing to stop him,” “Can do whatever he wants,” “handles HTML like a real Chad,” “Doesn’t fear HTML,” “can work anonymously,” Python Requests-HTML library logo, “Even Javascript can’t stop him.”
Thanks for the edit. Part of the reason I’m spamming that bot so much is to see how it handles different images, and partly so people know that it exists if they ever want a quick and dirty OCR scan of images in a post or comment.
I’ve been meaning to learn more libreddit, teddit, nitter et al obtain reddit and twitter data. I am 90% sure they don’t use official APIs so it has to be scraping. I tried looking at the libreddit code once but it made no sense to me (skill issue).
Edit: looks like libreddit uses the api
As a Selenium user, I agree with this image. :)
Image 1 text
Virgin API Consumer {JSON} poso Chad Independent Scraper follows no rules, doesn’t agree to any terms of service Fears HTML Limited to the what the API can do Has to identify himself even for read-only APIs A slave to the API provider son Has to worry about quota Thinks that he is making his life easier API keys has to agree to Terms of Service and follow the the rules Even Javascript can’t stop him Se Rettests- can work anonymously has no limitations can access any data he wants His software is always independent Doesn’t care about changes in policies Doesn’t fear HTML handles HTML like a real Chad h do whatever he wants Websites can do nothing to stop him Tokens
This action was performed by a bot.
I used to think projects like Nitter or NewPipe were a bit overzealous, scraping the webpage or using the webpage’s API rather than the official API, but it’s starting to look like simply less of a pain in the butt. 🙃
get bit too many times and you start wearing gloves.
Yeah, I just could not imagine a scenario where these companies would close up their API. You don’t offer an API as a service toward others. You offer it, so 3rd party devs don’t scrape your webpage, which is not an ‘API’ you want to keep stable. It’s a service toward your own devs.
API - Adversarial Programming Interface
I don’t use apps, but if they get rid of old.reddit.com I’m done. I’ve been on Reddit since the Digg migration and Digg for several years prior. It’s high time to ditch corporate backed social media. I’ve been enjoying Mastodon recently, so time to join Lemmy too. The Reddit ship is sinking and has been for years (since the stupid redesign) but there’s not much left above water at this point.
Mastodon’s cool but I don’t know why they immediately removed features people find valuable in the app it’s modeled after
If it affects alternative frontends like libreddit, teddit, etc., that will be enough for me to almost completely quit browsing.
Events like this are unpredictable, and it is why places like Lemmy need to always be ready to receive and retain users. I lost some interest because I felt the main instances had similar problems (culturally) to reddit instead of trying to be something better, and that community feedback seemed to go unreceived. The technology can help, but the rest is up to people putting in extra effort.
Yes there is definitely a lack in variety regarding instances. So people just need to go ahead and create new ones.
Might be the beginning of the end for Reddit and might have similar effects for Lemmy as it had for Mastodon.
I suspect the sign up process here might impede such a thing.
And…now I’m here. I guess I hope that works out for them.
It’s funny because I just recently created a tiny web app that I run off my own computer which allows me to aggregate the feeds of any subreddit I want along with posts from Lemmy and other Reddit-like forums. Because of this, this change won’t really affect me. While I do occasionally use a third party Reddit app to surf Reddit, I mostly just use my web app and it doesn’t use any Reddit APIs but just scrapes the website directly. Only thing is I’ve heard that they might be getting rid of old Reddit. I currently scrape from old Reddit rather than the new one because the old one has easier HTML objects to identify. Still, it shouldn’t be too hard start scraping the new UI, if I have to.
you might want to get in contact with the folks at libreddit who are concerned anonymous endpoints will be closed - thus killing libreddit and teddit
interesting. It looks like libreddit at least would be squashed.
In that issue they’re saying “hmm I wonder if this would apply to unauthenticated API requests”.
It seems nonsensical to me that it wouldn’t apply to unauthenticated API requests.
according to their matrix room teddit will meet the same fate
@Elara@lemmygrad.ml this may have implications for the TankieReplyBot.
TankieReplyBot doesn’t run on Reddit, it’s Lemmy only. This won’t affect it.
Wouldn’t the API changes for reddit cause some of the privacy frontends it links to (like libreddit and teddit) to no longer work though?
Oh, that’s what you meant. Yeah, that could be an issue, but I imagine at least some hosts will pay for the API if it affects them, depending on how much it costs. Hopefully they can continue to work. If not, it might be time to do some web scraping and get around the API.
It begins. Not too long a step until they start charging app developers and various clients for usage. If the goal is to funnel people to using only their official apps, like twitter, fb, and instagram do, they need to start this as a first step.
deleted by creator
They would need to make their webpage only accessible with a login, or try to obfuscate it as hard as Instagram does, otherwise 3rd-party devs will scrape that. And that would hurt their discoverability massively.
I mean, it does have the same self-destructive energy as closing up your API, so I’m not saying they won’t do it, but it would be stupid.
Stupidmove motived by greed on their part but good for Lemmy
I was wondering about libreddit and teddit as well lol.
Reddit’s announcement made me open lemmy to check the discussion happening here lol. Now I’ll check hackernews as well.
Also, can someone help me access other instances from the jerbora app? I’m a bit new to lemmy. I can’t seem to get it working by following the official help pages. The three dot on the top right of the search bar tab doesn’t seem to work and I’m not sure what that is for.
You can subscribe to federated communities that have already been connected, within the jerboa UI. Click the communities button at the bottom, then go to them.
But unfortunately you can’t do the initial connection yet within jerboa… that only works through the lemmy-ui search bar atm.
Thanks for the answer. I’ll give it a try.
Update: I got it working. Thanks a bunch.
How do you do a search for a not yet federated community through the lemmy ui anyway? For instance, if I try to get this quantum computing community from lemmygrad, every time I try to search for it I can’t find it. This is the query I’m using
Your query looks fine… might be something going on with that community specifically. I just tried this one and it worked fine: https://lemmygrad.ml/c/biology@mander.xyz
When you searched for that community, what was your query? Was it the full url (i.e. https://lemmygrad.ml/c/biology@mander.xyz), or was it !<community name>@<instance domain>?
Either format should work, you can test it with other as yet unfederated communities.
And reddit will go the way of Digg if they continue on doing this nonsense.
Initially I my response was “big whoop” I just realized that I pretty much only use reddit through RIF. I won’t pay a subscription, so guess I’ll mostly be done with reddit.
Hopefully the communities on reddit will have a bit more usage on lemmy in the near future.
Here’s a post from the Apollo app developer about how it affects 3rd party apps: https://www.reddit.com/r/apolloapp/comments/12ram0f/had_a_few_calls_with_reddit_today_about_the/
A Reddit link was detected in your comment. Here are links to the same location on Teddit and Libreddit, which are Reddit frontends that protect your privacy.
This is a really interesting read; although I believe there is still some resentment when he changed from Pro to Ultra. As someone who purchased both it wasn’t the best user experience.
Reading through, it makes sense unlike Twitter’s policy change. Why should tech giants have access to Reddit’s API on Reddit’s dime at no benefit to Reddit or Reddit’s users? As long as users are able to keep running bots and alternative apps, I don’t see a problem. I just hope that they would allow free academic licenses.
The thing is whether privacy oriented frontends will be requested to pay or not. Cause one of the ways to detect whether one is a regular user, or something else, might be user accesses or requests. A frontend instance is in fact a 3rd party, and most probably will be detected as such, therefore privacy oriented frontends will vanish, as the ones for twitter did, right?
What’s up with this comment? It’s not deleted or removed, but it has no content.
I’m wondering if they posted an invisible character just to fool us.
deleted by creator
Reddit could add anti-bot restrictions, but they don’t, because bots drive up their “engagement” numbers. This is entirely two-faced. They essentially just want to make some money off of something they already see as benefitting them.
I was thinking specifically of bots that are associated with a community, like moderation aids or Wheel of Time’s Lews Therin quote bot. I’m not sure the bots you’re thinking of actually do increase engagement numbers if they can be detected. Advertisers are only interested in human eyeballs.
Advertisers are only interested in human eyeballs.
Very true, but this reveals the conflicts of interest between these social media companies, and the advertisers they sell space to. They want to say to advertisers: buy an ad on our site, it will reach thousands of real people! See all this activity! When in reality a lot of that activity is bot generated.
Both advertisers and users want to reach and talk to real people, but it’s in these social media companies interest to inflate their numbers and fake engagement any way they can.
This isn’t a small problem either, I’ve heard it said that half of all tweets, and a good percentage of youtube comments are from bots.
It’s even a reason for those companies not to sell “no advertisement” subscriptions to their users. Reddit could offer something like that, but it would mean to lose the most valuable eyeballs (which belong to the humans who can afford to pay for not seeing ads) when it comes to marketing the website to advertisers.