Mozilla’s innovation group and Justine Tunney just released llamafile, and I think it’s now the single best way to get started running Large Language Models (think your own local copy …
Seems like 4gb of RAM is enough for the smaller models, and then it’s just a difference of how fast it generates the responses based on how good the CPU is.


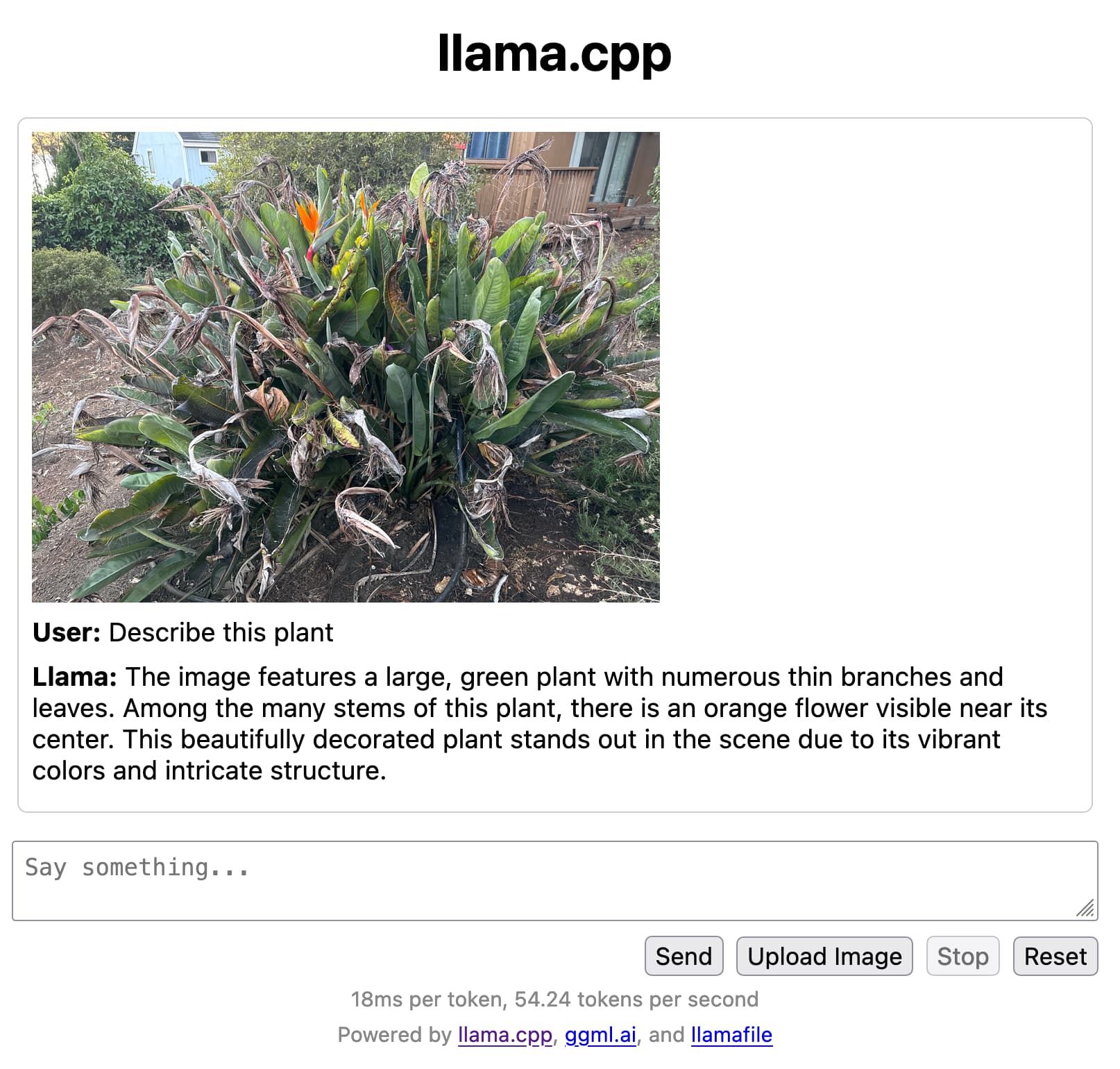
Seems like 4gb of RAM is enough for the smaller models, and then it’s just a difference of how fast it generates the responses based on how good the CPU is.