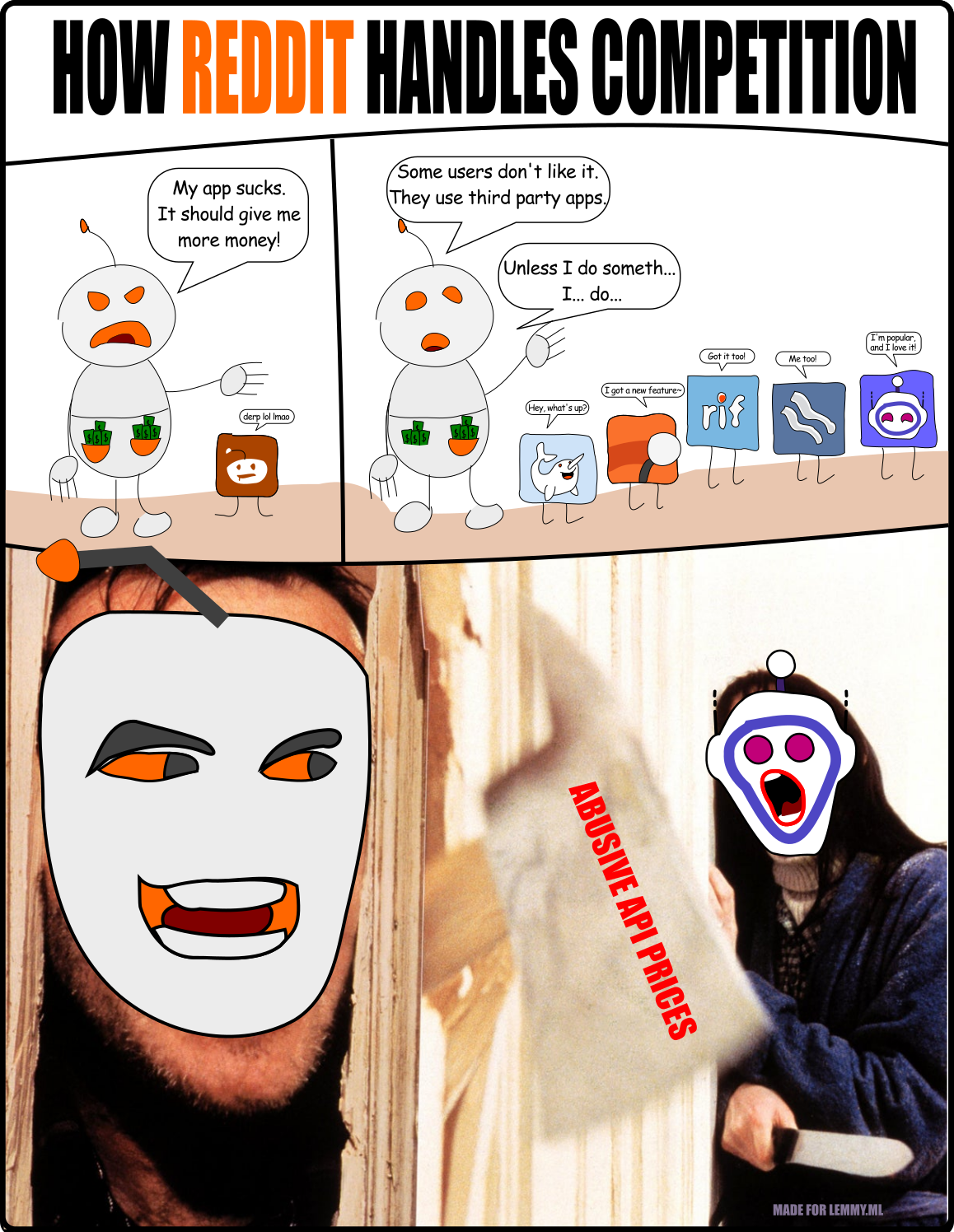
I listened to the interview of Apollo’s dev, and the interviewer brought up a good point (the only good point I’ve heard on the other side of this). Natural language models are becoming very popular, and lots of companies are building them. To do this, they are scraping the web, and especially places like Reddit. It sounds like Reddit wants to capitalize on this by increasing their API’s to these (absurdly) high prices.
I mentioned this in another discussion, but even if Reddit is trying to milk the people paying to access the API for data models for NLP, this is still a bad move. Even the ones who stay behind in Reddit will be less engaged; and lack of engagement in this case means shorter, decontextualised sentences, conveying almost nothing. It’s the difference between a well-thought reply and a “lol”.
So the data will quickly become useless, and even the ones who might pay for it at the start will eventually say “why bother? Reddit only adds noise to our models.” and stop paying.
And it’s a bit off-topic, but about NLP, I think that brute-forcing (feed it more data) is counter-productive in the long run, too. Humans actually learn language (how to use it, not just how to utter grammatically sound but meaningless sentences) with considerably less exposure.
Yes, very good points. I am not a ML expert by any means, but it does seem like companies are in a bit of an arms race right now, and are just trying to grow large models without doing it properly.


{kind=link}
I listened to the interview of Apollo’s dev, and the interviewer brought up a good point (the only good point I’ve heard on the other side of this). Natural language models are becoming very popular, and lots of companies are building them. To do this, they are scraping the web, and especially places like Reddit. It sounds like Reddit wants to capitalize on this by increasing their API’s to these (absurdly) high prices.
I mentioned this in another discussion, but even if Reddit is trying to milk the people paying to access the API for data models for NLP, this is still a bad move. Even the ones who stay behind in Reddit will be less engaged; and lack of engagement in this case means shorter, decontextualised sentences, conveying almost nothing. It’s the difference between a well-thought reply and a “lol”.
So the data will quickly become useless, and even the ones who might pay for it at the start will eventually say “why bother? Reddit only adds noise to our models.” and stop paying.
And it’s a bit off-topic, but about NLP, I think that brute-forcing (feed it more data) is counter-productive in the long run, too. Humans actually learn language (how to use it, not just how to utter grammatically sound but meaningless sentences) with considerably less exposure.
Yes, very good points. I am not a ML expert by any means, but it does seem like companies are in a bit of an arms race right now, and are just trying to grow large models without doing it properly.